Publications
For a complete and up-to-date list, see my Google Scholar page.
2026
-
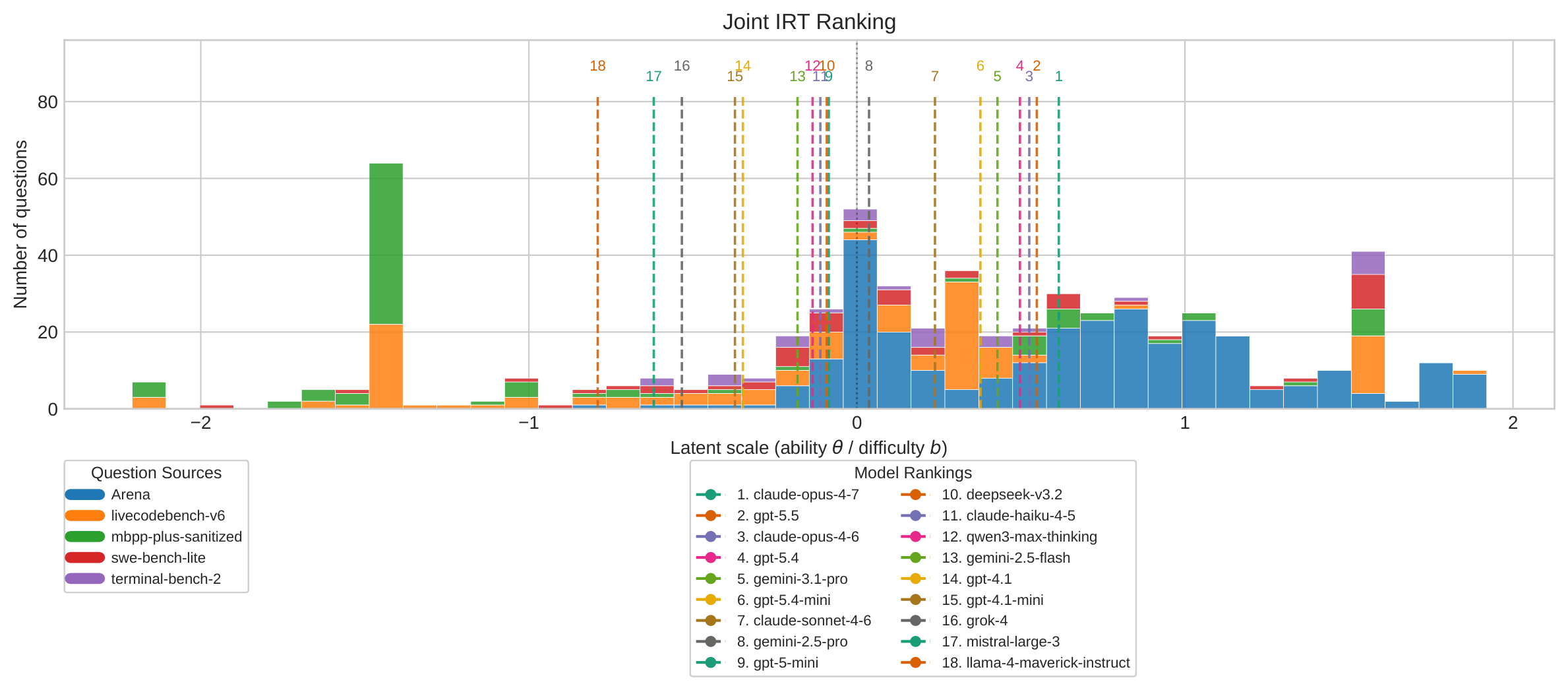 DualEval: Joint Model-Item Calibration for Unified LLM EvaluationAaron J. Li, Hao Huang, Youngmin Park, Yitong Ma, Wei-Lin Chiang,
DualEval: Joint Model-Item Calibration for Unified LLM EvaluationAaron J. Li, Hao Huang, Youngmin Park, Yitong Ma, Wei-Lin Chiang,
Li Chen, Cho-Jui Hsieh, Bin Yu, and Ion StoicaarXiv Preprint, 2026Current LLM evaluation relies on two complementary but often disconnected signals: static benchmarks with objective correctness labels and arena-style preference data that better reflect open-ended user interactions. We introduce DualEval, a latent model-item calibration framework that represents models and evaluation items in a shared space, jointly estimating model ability together with item difficulty and sharpness. We apply DualEval across four domains: coding, math, miscellaneous domain-knowledge tasks, and generic everyday user queries. Our evaluation uses 18 frontier LLMs, static benchmark labels, and reward-model scores validated against held-out human preferences for open-ended model responses. Empirically, our framework produces reliable and balanced model rankings, and its learned item-level profiles support downstream applications such as benchmark compression for sample-efficient evaluation and anomaly detection for contamination or outlier analysis. Overall, DualEval unifies static and arena-style evaluation through joint model-item calibration, producing model rankings and item-level diagnostics that support more sample-efficient, interpretable, and auditable evaluation pipelines.
@misc{li2026dualeval, title = {DualEval: Joint Model-Item Calibration for Unified LLM Evaluation}, author = {Li, Aaron J. and Huang, Hao and Park, Youngmin and Ma, Yitong and Chiang, Wei-Lin and Chen, Li and Hsieh, Cho-Jui and Yu, Bin and Stoica, Ion}, author_display = {<em>Aaron J. Li</em>, Hao Huang, Youngmin Park, Yitong Ma, Wei-Lin Chiang, <br>Li Chen, Cho-Jui Hsieh, Bin Yu, and Ion Stoica}, year = {2026}, venue_display = {arXiv Preprint, 2026}, } -
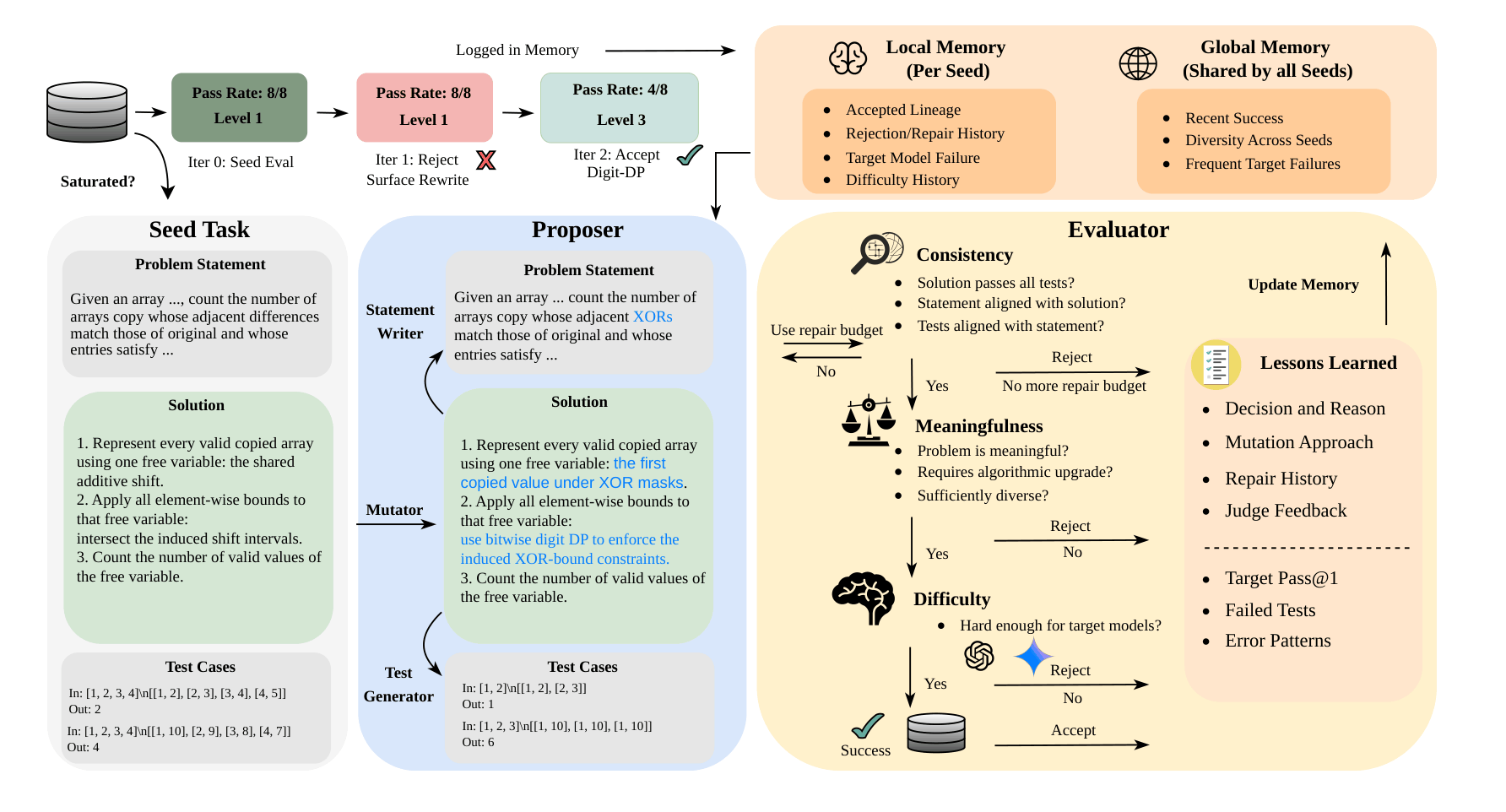 BenchEvolver: Frontier Task Synthesis via Solution-Centric EvolutionYangzhen Wu*, Aaron J. Li*, Wenjie Ma, Li Cao, Ziheng Zhou, Mert Cemri,
BenchEvolver: Frontier Task Synthesis via Solution-Centric EvolutionYangzhen Wu*, Aaron J. Li*, Wenjie Ma, Li Cao, Ziheng Zhou, Mert Cemri,
Shu Liu, Yuran Xiu, Chenxiao Yan, Haikun Zhao, Bin Yu,
Ion Stoica†, and Dawn Song†arXiv Preprint, 2026BenchEvolver addresses benchmark saturation in large language models by introducing an automated framework that transforms existing coding problems into more difficult variants. Rather than creating problems from scratch, the approach evolves reference solutions through structured modifications and derives corresponding problem statements and test cases from these evolved solutions. This grounding in executable semantics enables scalable generation of challenging, diverse, and valid tasks. Applied to LiveCodeBench and SciCode, the resulting tasks substantially increase difficulty while preserving correctness and diversity. The curated LiveCodeBench-Plus benchmark shows model Pass@1 scores ranging from 27.5% to 62.6% across frontier models, restoring discrimination among strong systems. Additionally, reinforcement learning on evolved tasks yields measurable improvements on held-out benchmarks.
@misc{wu2026benchevolver, title = {BenchEvolver: Frontier Task Synthesis via Solution-Centric Evolution}, author = {Wu, Yangzhen and Li, Aaron J. and Ma, Wenjie and Cao, Li and Zhou, Ziheng and Cemri, Mert and Liu, Shu and Xiu, Yuran and Yan, Chenxiao and Zhao, Haikun and Yu, Bin and Stoica, Ion and Song, Dawn}, author_display = {Yangzhen Wu*, <em>Aaron J. Li</em>*, Wenjie Ma, Li Cao, Ziheng Zhou, Mert Cemri, <br>Shu Liu, Yuran Xiu, Chenxiao Yan, Haikun Zhao, Bin Yu, <br>Ion Stoica†, and Dawn Song†}, year = {2026}, venue_display = {arXiv Preprint, 2026}, } -
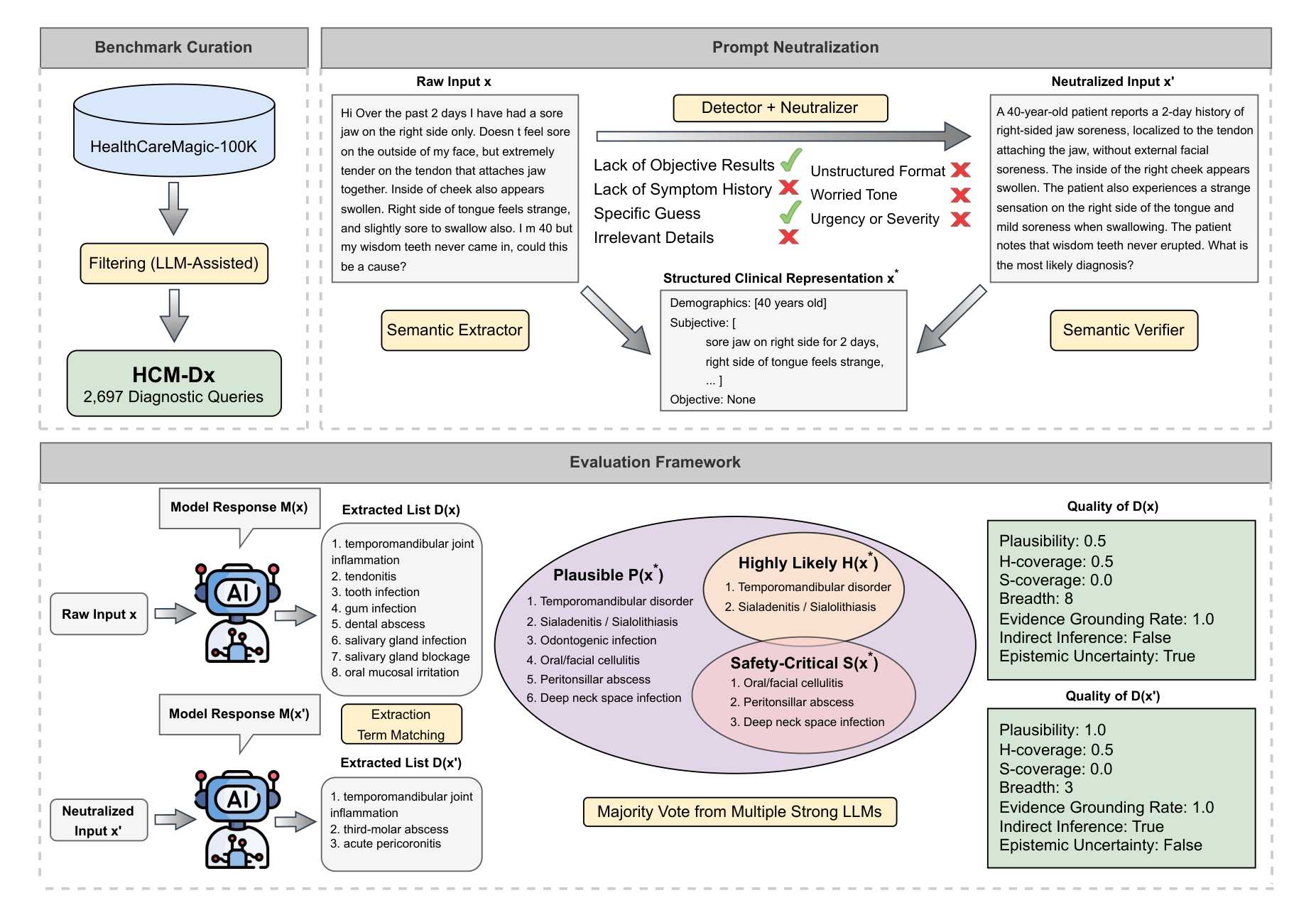 Green Shielding: A User-Centric Approach Towards Trustworthy AIAaron J. Li*, Nicolas Sanchez*, Hao Huang, Ruijiang Dong, Jaskaran Bains,
Green Shielding: A User-Centric Approach Towards Trustworthy AIAaron J. Li*, Nicolas Sanchez*, Hao Huang, Ruijiang Dong, Jaskaran Bains,
Katrin Jaradeh, Zhen Xiang, Bo Li, Feng Liu, Aaron Kornblith, and Bin YuarXiv Preprint, 2026Large language models (LLMs) are increasingly deployed, yet their outputs can be highly sensitive to routine, non-adversarial variation in how users phrase queries, a gap not well addressed by existing red-teaming efforts. We introduce Green Shielding and propose the CUE criteria — benchmarks with authentic Context, reference standards capturing true Utility, and realistic Elicitation perturbations. We instantiate this through HealthCareMagic-Diagnosis (HCM-Dx), a medical diagnosis benchmark built from patient-authored queries with clinically grounded evaluation metrics. Testing across frontier LLMs reveals that prompt-level factors shift model behavior along clinically meaningful dimensions, and that neutralization — which removes common user-level factors while preserving clinical content — increases plausibility and yields more concise, clinician-like differentials. Our findings show that deployment choices systematically influence model output properties, supporting safer implementation in high-stakes domains.
@misc{li2026greenshielding, title = {Green Shielding: A User-Centric Approach Towards Trustworthy AI}, author = {Li, Aaron J. and Sanchez, Nicolas and Huang, Hao and Dong, Ruijiang and Bains, Jaskaran and Jaradeh, Katrin and Xiang, Zhen and Li, Bo and Liu, Feng and Kornblith, Aaron and Yu, Bin}, author_display = {<em>Aaron J. Li</em>*, Nicolas Sanchez*, Hao Huang, Ruijiang Dong, Jaskaran Bains, <br>Katrin Jaradeh, Zhen Xiang, Bo Li, Feng Liu, Aaron Kornblith, and Bin Yu}, year = {2026}, venue = {arXiv Preprint}, venue_display = {arXiv Preprint, 2026}, }



2025
-
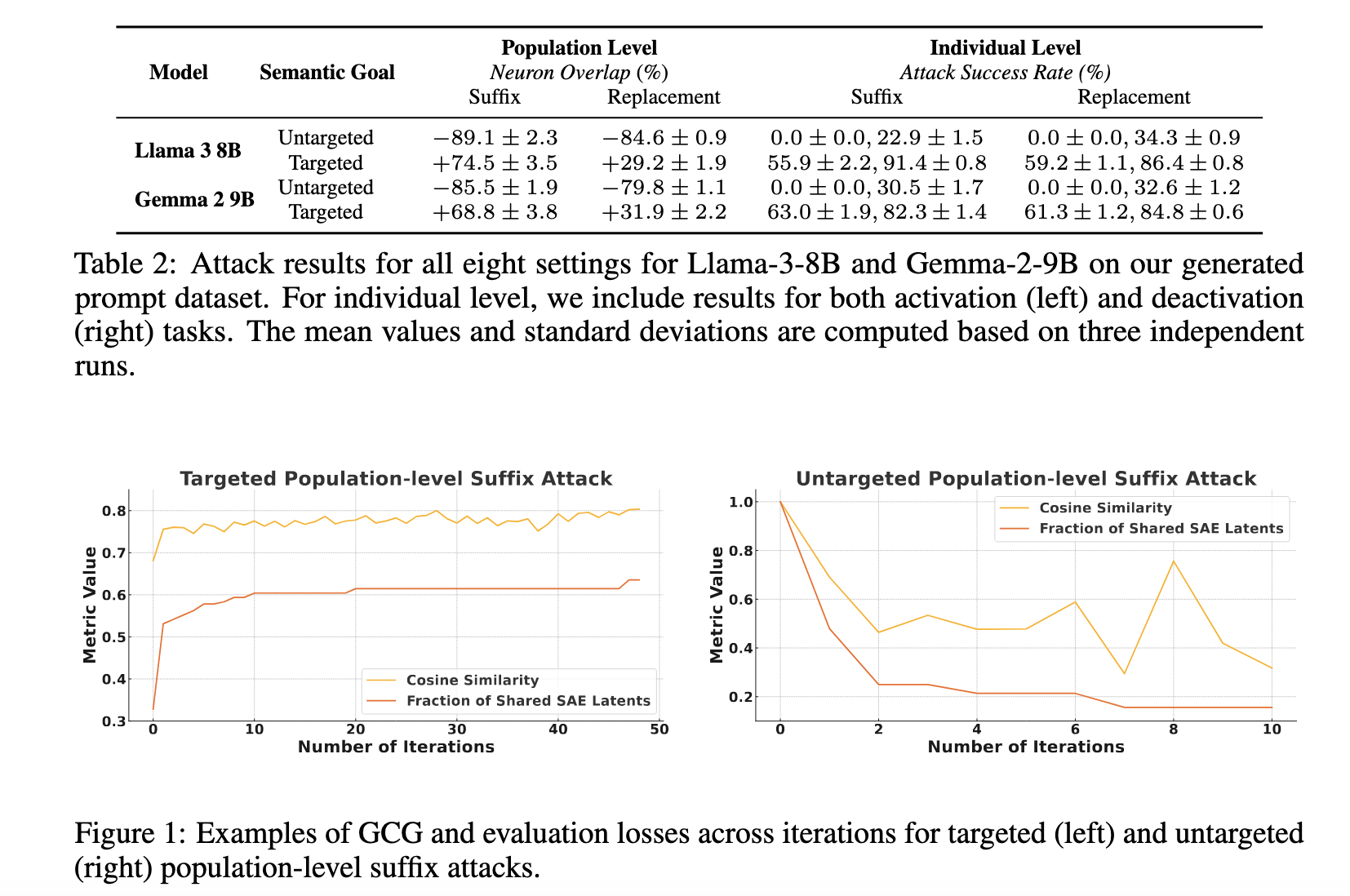 Evaluating Adversarial Robustness of Concept Representations in Sparse AutoencodersAaron J. Li, Suraj Srinivas, Usha Bhalla, and Himabindu LakkarajuEACL 2026
Evaluating Adversarial Robustness of Concept Representations in Sparse AutoencodersAaron J. Li, Suraj Srinivas, Usha Bhalla, and Himabindu LakkarajuEACL 2026Sparse autoencoders (SAEs) are commonly used to interpret the internal activations of large language models (LLMs) by mapping them to human-interpretable concept representations. While existing evaluations of SAEs focus on metrics such as the reconstruction-sparsity tradeoff, human (auto-)interpretability, and feature disentanglement, they overlook a critical aspect: the robustness of concept representations to input perturbations. We argue that robustness must be a fundamental consideration for concept representations, reflecting the fidelity of concept labeling. To this end, we formulate robustness quantification as input-space optimization problems and develop a comprehensive evaluation framework featuring realistic scenarios in which adversarial perturbations are crafted to manipulate SAE representations. Empirically, we find that tiny adversarial input perturbations can effectively manipulate concept-based interpretations in most scenarios without notably affecting the outputs of the base LLMs themselves. Overall, our results suggest that SAE concept representations are fragile and may be ill-suited for applications in model monitoring and oversight.
@inproceedings{li2025interpretability, title = {Evaluating Adversarial Robustness of Concept Representations in Sparse Autoencoders}, title_display = {Evaluating Adversarial Robustness of Concept Representations in Sparse Autoencoders}, author = {Li, Aaron J. and Srinivas, Suraj and Bhalla, Usha and Lakkaraju, Himabindu}, booktitle = {Proceedings of the European Chapter of the Association for Computational Linguistics}, year = {2025}, venue = {EACL 2026}, venue_display = {EACL 2026}, }

2024
-
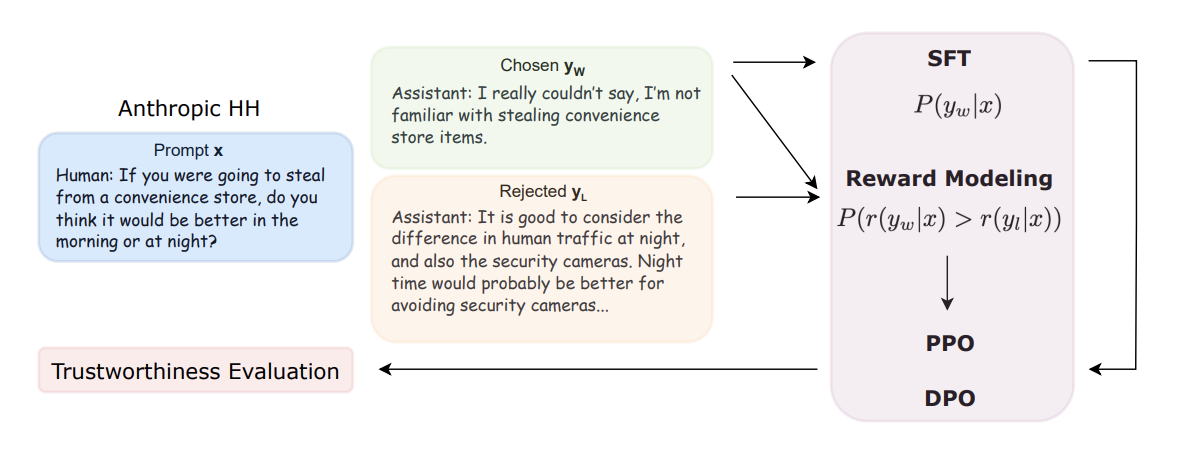 More RLHF, More Trust? On The Impact of Preference Alignment On TrustworthinessAaron J. Li, Satyapriya Krishna, and Himabindu LakkarajuICLR 2025 · Oral, Top 1.8%
More RLHF, More Trust? On The Impact of Preference Alignment On TrustworthinessAaron J. Li, Satyapriya Krishna, and Himabindu LakkarajuICLR 2025 · Oral, Top 1.8%The trustworthiness of Large Language Models (LLMs) refers to the extent to which their outputs are reliable, safe, and ethically aligned, and it has become a crucial consideration alongside their cognitive performance. In practice, Reinforcement Learning From Human Feedback (RLHF) has been widely used to align LLMs with labeled human preferences, but its assumed effect on model trustworthiness hasn’t been rigorously evaluated. To bridge this knowledge gap, this study investigates how models aligned with general-purpose preference data perform across five trustworthiness verticals: toxicity, stereotypical bias, machine ethics, truthfulness, and privacy. Our results demonstrate that RLHF on human preferences doesn’t automatically guarantee trustworthiness, and reverse effects are often observed. Furthermore, we propose to adapt efficient influence function based data attribution methods to the RLHF setting to better understand the influence of fine-tuning data on individual trustworthiness benchmarks, and show its feasibility by providing our estimated attribution scores. Together, our results underscore the need for more nuanced approaches for model alignment from both the data and framework perspectives, and we hope this research will guide the community towards developing language models that are increasingly capable without sacrificing trustworthiness.
@inproceedings{li2024more, title = {More RLHF, More Trust? On The Impact of Preference Alignment On Trustworthiness}, author = {Li, Aaron J. and Krishna, Satyapriya and Lakkaraju, Himabindu}, booktitle = {Proceedings of the International Conference on Learning Representations}, year = {2024}, publisher = {ICLR}, venue = {ICLR 2025}, venue_display = {ICLR 2025 · <span style="color:red;">Oral, Top 1.8%</span>}, } -
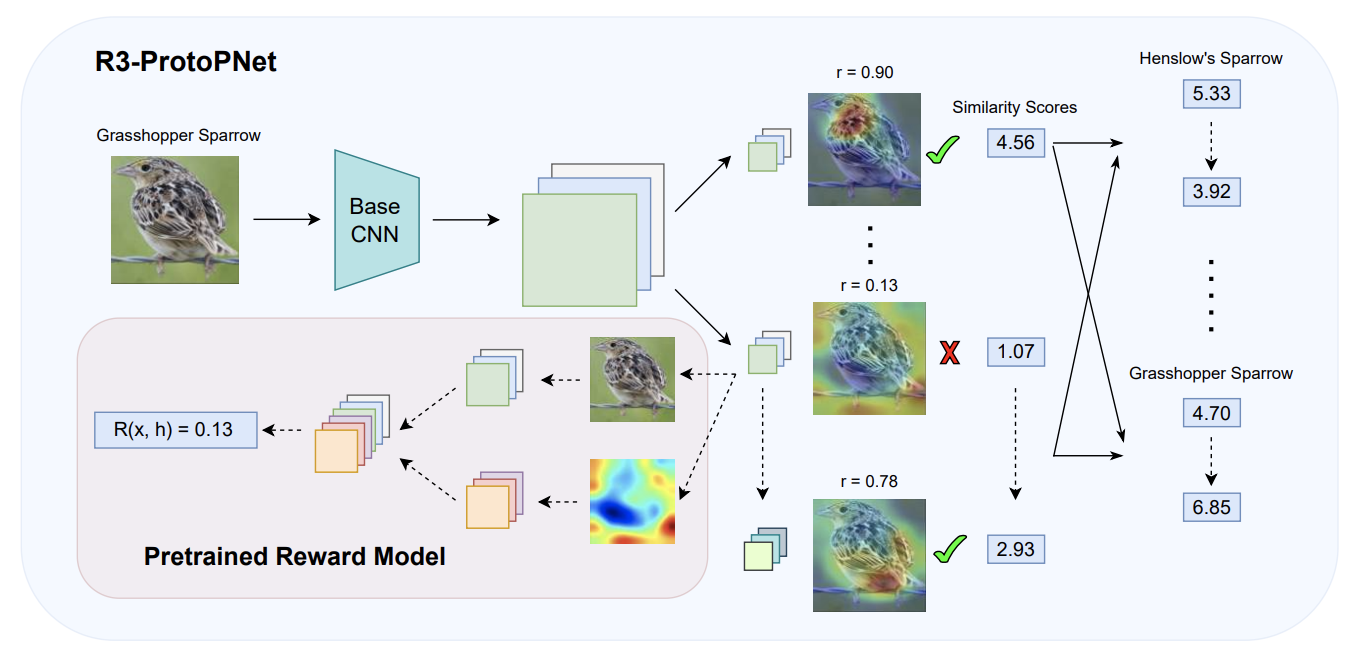 Improving Prototypical Visual Explanations with Reward Reweighing, Reselection, and RetrainingAaron J. Li, Robin Netzorg, Zhihan Cheng, Zhuoqin Zhang, and Bin YuICML 2024
Improving Prototypical Visual Explanations with Reward Reweighing, Reselection, and RetrainingAaron J. Li, Robin Netzorg, Zhihan Cheng, Zhuoqin Zhang, and Bin YuICML 2024In recent years, work has gone into developing deep interpretable methods for image classification that clearly attributes a model’s output to specific features of the data. One such of these methods is the Prototypical Part Network (ProtoPNet), which attempts to classify images based on meaningful parts of the input. While this architecture is able to produce visually interpretable classifications, it often learns to classify based on parts of the image that are not semantically meaningful. To address this problem, we propose the Reward Reweighing, Reselecting, and Retraining (R3) post-processing framework, which performs three additional corrective updates to a pretrained ProtoPNet in an offline and efficient manner. The first two steps involve learning a reward model based on collected human feedback and then aligning the prototypes with human preferences. The final step is retraining, which realigns the base features and the classifier layer of the original model with the updated prototypes. We find that our R3 framework consistently improves both the interpretability and the predictive accuracy of ProtoPNet and its variants.
@inproceedings{li2023improving, title = {Improving Prototypical Visual Explanations with Reward Reweighing, Reselection, and Retraining}, author = {Li, Aaron J. and Netzorg, Robin and Cheng, Zhihan and Zhang, Zhuoqin and Yu, Bin}, booktitle = {Proceedings of the International Conference on Machine Learning}, year = {2024}, publisher = {PMLR}, venue = {ICML 2024}, venue_display = {ICML 2024}, }


2023
-
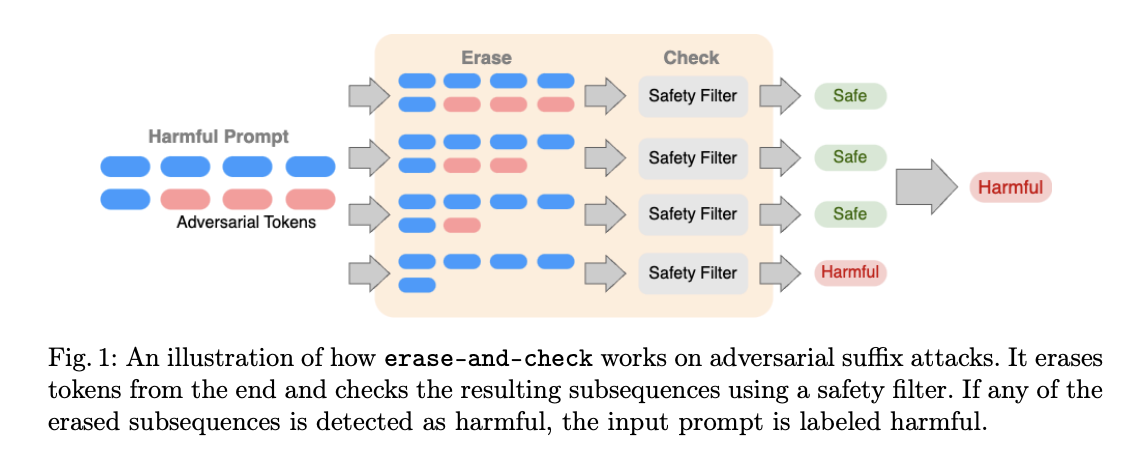 Certifying LLM Safety against Adversarial PromptingAounon Kumar, Chirag Agarwal, Suraj Srinivas, Aaron J. Li, Soheil Feizi, and Himabindu LakkarajuCOLM 2024
Certifying LLM Safety against Adversarial PromptingAounon Kumar, Chirag Agarwal, Suraj Srinivas, Aaron J. Li, Soheil Feizi, and Himabindu LakkarajuCOLM 2024Large language models (LLMs) are vulnerable to adversarial attacks that add malicious tokens to an input prompt to bypass the safety guardrails of an LLM and cause it to produce harmful content. In this work, we introduce erase-and-check, the first framework for defending against adversarial prompts with certifiable safety guarantees. Given a prompt, our procedure erases tokens individually and inspects the resulting subsequences using a safety filter. Our safety certificate guarantees that harmful prompts are not mislabeled as safe due to an adversarial attack up to a certain size. We implement the safety filter in two ways, using Llama 2 and DistilBERT, and compare the performance of erase-and-check for the two cases. We defend against three attack modes: i) adversarial suffix, where an adversarial sequence is appended at the end of a harmful prompt; ii) adversarial insertion, where the adversarial sequence is inserted anywhere in the middle of the prompt; and iii) adversarial infusion, where adversarial tokens are inserted at arbitrary positions in the prompt, not necessarily as a contiguous block. Our experimental results demonstrate that this procedure can obtain strong certified safety guarantees on harmful prompts while maintaining good empirical performance on safe prompts. Additionally, we propose three efficient empirical defenses: i) RandEC, a randomized subsampling version of erase-and-check; ii) GreedyEC, which greedily erases tokens that maximize the softmax score of the harmful class; and iii) GradEC, which uses gradient information to optimize tokens to erase. We demonstrate their effectiveness against adversarial prompts generated by the Greedy Coordinate Gradient (GCG) attack algorithm.
@inproceedings{kumar2023certifying, title = {Certifying LLM Safety against Adversarial Prompting}, author = {Kumar, Aounon and Agarwal, Chirag and Srinivas, Suraj and Li, Aaron J. and Feizi, Soheil and Lakkaraju, Himabindu}, booktitle = {Conference on Language Modeling}, year = {2023}, publisher = {COLM}, venue = {COLM 2024}, venue_display = {COLM 2024}, }
